商品信息与新闻信息的批量采集方法
在现代数据驱动的商业环境中,批量采集商品信息和新闻信息对于市场分析、竞争情报、内容聚合等应用至关重要。本文将介绍如何系统地进行商品信息和新闻信息的批量采集,包括常用工具、操作步骤以及注意事项。
商品信息批量采集方法
商品信息包括产品名称、价格、描述、图片、库存、评论等。批量采集通常涉及以下步骤:
- 确定采集目标:明确需要采集的商品信息源,如电商平台(淘宝、京东、亚马逊)、独立网站或API接口。
- 选择采集工具:
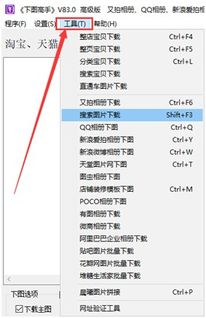
- 网络爬虫工具:使用Python的Scrapy、Beautiful Soup库,或可视化工具如八爪鱼、火车头采集器。这些工具可以模拟浏览器行为,抓取网页内容。
- API接口:如果目标平台提供开放API(如亚马逊API),可直接调用以获取结构化数据,效率更高且合规。
- 浏览器扩展:如Web Scraper插件,适合小规模、非编程用户。
- 设置采集规则:定义URL列表、提取字段(如价格、标题)和翻页逻辑。对于动态加载的内容(如AJAX),可能需要模拟JavaScript执行。
- 处理反爬机制:许多网站设有反爬虫措施,如IP限制、验证码。应对策略包括:
- 使用代理IP轮换。
- 设置合理的请求间隔(如每秒1-2次)。
- 模拟真实用户行为(添加User-Agent头)。
- 数据清洗与存储:采集后,去除重复、错误数据,并转换为结构化格式(如CSV、JSON或数据库)。工具如Pandas(Python)可辅助数据处理。
- 合规性检查:确保采集行为符合目标网站的Robots协议和法律法规,避免侵犯隐私或知识产权。
新闻信息批量采集方法
新闻信息通常包括标题、正文、发布时间、来源和分类。批量采集流程与商品信息类似,但需注意新闻源的时效性和多样性。
- 确定新闻源:选择权威网站(如新华社、新浪新闻)、聚合平台(如Google新闻)或RSS订阅源。RSS是高效的采集方式,提供标准化的数据格式。
- 选择采集工具:
- RSS阅读器或解析器:使用Python的feedparser库解析RSS源,快速获取最新新闻。
- 网络爬虫:对于无RSS的网站,采用类似商品采集的方法,但需处理动态内容(如无限滚动)。
- 新闻API:如NewsAPI、百度新闻API,提供直接的数据接口,省去爬虫开发。
- 设置采集频率:新闻信息更新快,需设置定时任务(如每小时采集一次)。工具如cron(Linux)或APScheduler(Python)可自动化执行。
- 内容提取与去重:使用自然语言处理(NLP)技术提取关键信息,并基于标题或内容哈希值去重,避免重复采集。
- 存储与分析:将数据存入数据库(如MySQL或Elasticsearch),便于后续检索和分析趋势。
通用注意事项
- 法律与道德:遵守网站使用条款,避免过度采集导致服务器压力。对于敏感信息,确保符合GDPR等法规。
- 数据质量:定期验证采集数据的准确性,处理编码问题(如中文乱码)。
- 可扩展性:设计采集系统时,考虑模块化,便于添加新数据源。
批量采集商品和新闻信息需要结合技术工具与合规策略。对于初学者,建议从简单的API或RSS源入手,逐步扩展到复杂爬虫项目。通过高效采集,企业或个人可以快速获取市场动态,支撑决策与创新。
如若转载,请注明出处:http://www.fhtxsqb.com/product/14.html
更新时间:2026-06-18 01:09:48